Hadoop
下載地址
下載地址

Hadoop是一個由Apache基金會所開發(fā)能夠讓用戶輕松架構和使用的大規(guī)模數據處理平臺,是處理、存儲和分析海量的分布式、非結構化數據的開源框架。Hadoop的分布式架構,將大數據處理引擎盡可能的靠近存儲,并且它的MapReduce功能實現了將單個任務打碎,并將碎片任務(Map)發(fā)送到多個節(jié)點上,之后再以單個數據集的形式加載(Reduce)到數據倉庫里。Hadoop 是一種分析和處理大數據的軟件平臺,是一個用 Java 語言實現的 Apache 的開源軟件框架,在大量計算機組成的集群中實現了對海量數據的分布式計算。Hadoop具備可靠、高效、可伸縮等特點,用戶可以輕松地在Hadoop上開發(fā)和運行處理海量數據的應用程序。有需要使用Hadoop的朋友快通過kkx分享的地址來獲取吧!
1. 高可靠性。
Hadoop按位存儲和處理數據的能力值得人們信賴。
2. 高擴展性。
Hadoop是在可用的計算機集簇間分配數據并完成計算任務的,這些集簇可以方便地擴展到數以千計的節(jié)點中。
3. 高效性。
Hadoop能夠在節(jié)點之間動態(tài)地移動數據,并保證各個節(jié)點的動態(tài)平衡,因此處理速度非常快。
4. 高容錯性。
Hadoop能夠自動保存數據的多個副本,并且能夠自動將失敗的任務重新分配。
5. 低成本。
與一體機、商用數據倉庫以及QlikView、Yonghong Z-Suite等數據集市相比,hadoop是開源的,項目的軟件成本因此會大大降低。
Hadoop2.7.1的部署
機器環(huán)境:
操作系統(tǒng):CentOS 6.4 64位系統(tǒng)
Hadoop版本:hadoop-2.7.1,在CentOS下自行編譯后的64位版本。
1、首先下載安裝包tar zxvf hadoop-2.7.1.tar.gz
2.在虛擬機中解壓安裝包

3.安裝目錄下創(chuàng)建數據存放的文件夾,tmp、hdfs、hdfs/data、hdfs/name
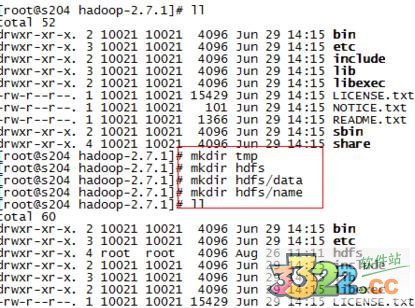
4、修改/home/yy/hadoop-2.7.1/etc/hadoop下的配置文件
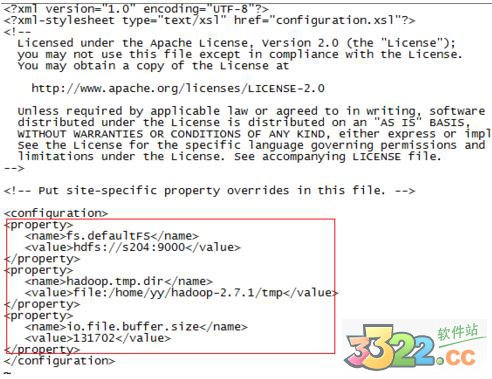
修改core-site.xml,加上
fs.defaultFS
hdfs://s204:9000
hadoop.tmp.dir
file:/home/yy/hadoop-2.7.1/tmp
io.file.buffer.size
131702
5.修改hdfs-site.xml,加上
dfs.namenode.name.dir
file:/home/yy/hadoop-2.7.1/dfs/name
dfs.datanode.data.dir
file:/home/yy/hadoop-2.7.1/dfs/data
dfs.replication
2
dfs.namenode.secondary.http-address
s204:9001
dfs.webhdfs.enabled
true

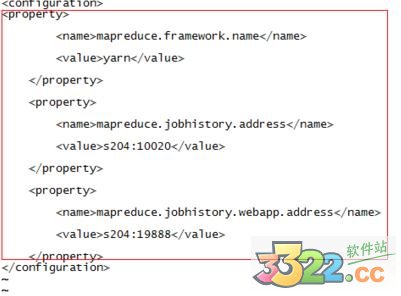
6.修改mapred-site.xml,加上
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
s204:10020
mapreduce.jobhistory.webapp.address
s204:19888
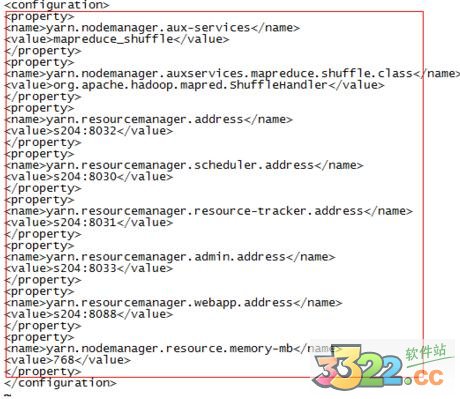
7.修改yarn-site.xml,加上
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
s204:8032
yarn.resourcemanager.scheduler.address
s204:8030
yarn.resourcemanager.resource-tracker.address
s204:8031
yarn.resourcemanager.admin.address
s204:8033
yarn.resourcemanager.webapp.address
s204:8088
yarn.nodemanager.resource.memory-mb
768
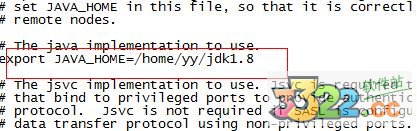
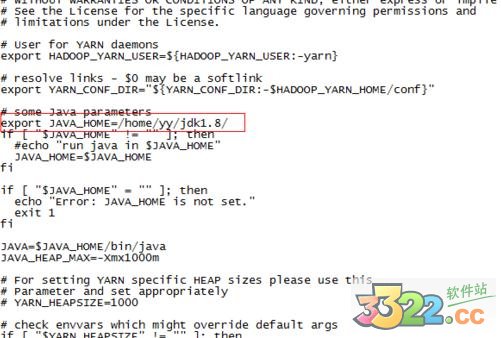
8、配置/home/yy/hadoop-2.7.1/etc/hadoop目錄下hadoop-env.sh、yarn-env.sh的JAVA_HOME,否則啟動時會報error
export JAVA_HOME=/home/yy/jdk1.8
9.配置/home/yy/hadoop-2.7.1/etc/hadoop目錄下slaves
加上你的從服務器,我這里只有一個s205
配置成功后,將hadhoop復制到各個從服務器上
scp -r /home/yy/hadoop-2.7.1 root@s205:/home/yy/

10.主服務器上執(zhí)行bin/hdfs namenode -format
進行初始化
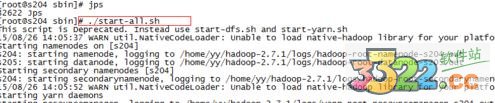
sbin目錄下執(zhí)行 ./start-all.sh
可以使用jps查看信息
停止的話,輸入命令,sbin/stop-all.sh
11.這時可以瀏覽器打開s204:8088查看集群信息啦
到此配置完成,如圖:
Hadoop V2.7.1免費版203MB返回頂部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下載站是專業(yè)的免費軟件下載站點,提供綠色軟件、免費軟件,手機軟件,系統(tǒng)軟件,單機游戲等熱門資源安全下載!
本站資源均收集整理于互聯網,其著作權歸原作者所有,如果有侵犯您權利的資源,請來信告知

 91U盤助手 V3.5無廣告版
91U盤助手 V3.5無廣告版 Daemon Tools虛擬光驅(支持win7、win10) V10.9漢化破解版
Daemon Tools虛擬光驅(支持win7、win10) V10.9漢化破解版 鴻業(yè)暖通空調軟件 v8.0完美破解版
鴻業(yè)暖通空調軟件 v8.0完美破解版 lockdir v5.75 綠色免費版
lockdir v5.75 綠色免費版 小點陣體 V6100.00官方版
小點陣體 V6100.00官方版 971款電子表格模板(Excel模板)
971款電子表格模板(Excel模板)  ASSSDBenchMark(硬盤測速) 綠色版
ASSSDBenchMark(硬盤測速) 綠色版 迅雷看看播放器 v6.1.1.603官方版
迅雷看看播放器 v6.1.1.603官方版